Recuento ponderado WWC
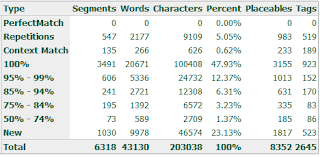
El recuento ponderado , que en inglés se conoce como Weighted Word Count (WWC), sirve para tener una estimación de cuánto esfuerzo nos llevará un determinado encargo . Veamos la siguiente imagen: Recuento de Trados 2009 Recibes de un cliente un archivo XML que, al abrirse, muestra unos datos similares a estos. Se trata de un análisis del recuento de repeticiones y coincidencias contra la(s) memoria(s) de traducción del cliente . El cliente te pregunta cuánto tardarás en entregarle el encargo. Suponemos que puedes completar 2500 palabras (revisión incluida) por día. 43 000 palabras entre 2500 = 17,2 días. El cliente ya ha puesto pies en polvorosa. 10 000 palabras nuevas entre 2500 = 4 días. El cliente acepta. Y tú te has metido en un lío porque no has tenido en cuenta la montaña de palabras que hay más arriba. Esto se resume así: no todas las palabras pesan igual. No todos los segmentos (≈frases) cuestan lo mismo de traducir. Están los segmentos sin coincidencia alguna, los qu